

What is machine learning?
Machine learning is a branch of artificial intelligence that seeks to make machines imitate the manner in which humans learn. It allows computer systems to analyze data, learn from it, identify patterns, and make decisions.
This method of data analysis focuses on automating the building of analytical models.
Machine learning algorithms use statistical models to analyze data, make classifications or predictions, derive insights from the data, and use those insights to inform future decisions, make the system increasingly accurate as it is used.
Why is machine learning important?
Machine learning is becoming increasingly important with the rising amount and range of data available today. It alliows organizations to analyze complex data and deliver accurate results quickly.
Machine learning helps process large amounts of data, predict conclusions, and identify patterns. These algorithms also help uncover hidden insights without being programmed to specifically find those insights.
How does machine learning work?
UC Berkeley segments machine learning algorithms into three components:
A decision process
The system uses input data to make a prediction about the pattern in the data that your algorithm is seeking.
An error function
It evaluates the accuracy of the model’s prediction. If known examples are available, the prediction can be compared to them. It also seeks to quantify the level of inaccuracy.
An updating/optimization process
The algorithm considers the inaccuracy and updates the weights so that the model will be more accurate the next time.
The process would typically be repeated by the algorithm till it meets a certain threshold of accuracy.
What are the four types of machine learning?
Here are the four types of machine learning algorithms:
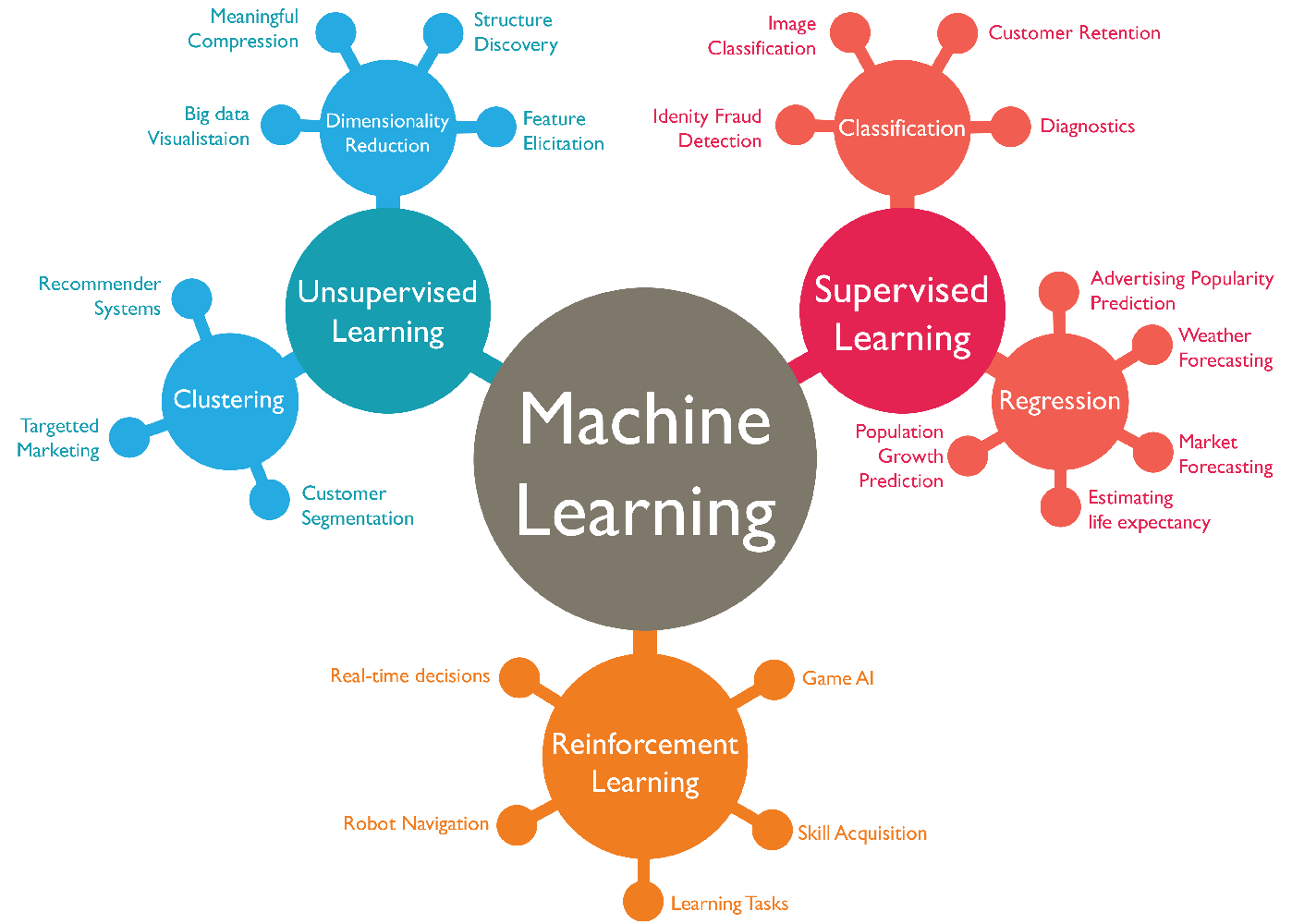
Supervised machine learning algorithms
In supervised machine learning, the model is trained using labeled data or examples. The algorithm then uses its learnings from this data to predict the output values. After it has been training to the right level, it can even provide targets for new inputs.
The algorithm can also compare its predicted outputs with the actual outputs and so that the model can be modified if there are any discrepancies.
In supervised machine learning, you have input variables as well as an output variable. Here you employ an algorithm to learn the mapping function from the input to the output.
Your aim is to approximate the mapping function to such an extent that when you use new input data, you are able to predict output variables for that data.
It is known as supervised machine learning because we know the correct answers and the process of an algorithm learning from the training dataset can be looked at as a teacher supervising the learning process.
The algorithm, in iterations, makes predictions on the training data and is corrected.
Supervised learning problems can be categorized as regression problems or classification problems.
- Classification problems: In classification problems, the output variable would be a category like ‘black’ and ‘white’ or ‘fit’ and ‘unfit’.
- Regression problems: In regression problems, the output variable would be a real value like ‘miles’, ‘pounds’, etc.
Unsupervised machine learning algorithms
These algorithms are training on data that is not labeled or classified. It examines how systems infer functions to describe hidden structures from unlabeled data.
Even though these systems don’t necessarily predict the right output, they draw inferences from the data and are able to describe hidden structures from unlabeled data that is fed to it.
In unsupervised machine learning, you only have the input data available to you and there are not any corresponding output variables available.
The objective of unsupervised machine learning is to model the underlying structure or distribution in the data for the purpose of learning more about the data.
Here there are no correct answers, so essentially there is no ‘teacher’. Unsupervised algorithms are essentially left on their own to figure everything out, discover and present facts about the data.
Unsupervised learning problems can be classified into clustering and association problems.
- Clustering problems: In such problems, you would be seeking to discover the inherent groupings in the data, like categorizing customers according to their buying behaviors.
- Association problems: In these problems, you would be trying to identify rules that describe large portions of your data. For example, people who buy a certain item also tend to buy another specific item.
Semi-supervised machine learning algorithms
Semi-supervised machine learning algorithms are generally trained on a little labeled data and a lot of unlabeled data. These algorithms are able to substantially increase their learning accuracy.
Reinforcement machine learning algorithms
Reinforcement machine learning algorithms are most significantly characterized by trial and error search and delayed rewards. It provides reinforcement signals (rewards) or punishments to allow the system to learn which action is the best and allows machines to determine the most appropriate behavior within a specific context on their own.
What is machine learning used for?
Machine learning is used for a range of activities, all the way from customer service to fraud detection. Here are some applications of machine learning:
Chatbots
Intelligent chatbots use machine learning to provide increasingly accurate responses to customer queries over time.
Recommendation engines
Recommendation engines like the ones used by Amazon, Netflix, and Spotify use machine learning algorithms to study the user’s consumption patterns and recommend products and content that the user would be most likely to consume and enjoy.
Speech recognition
Speech-to-text, aka, automatic speech recognition (ASR), or computer speech recognition is used to transform human speech into text data. It employs machine learning and Natural Language Processing (NLP) for this purpose.
Computer Vision
This is used for self-driving cars, radiology imaging in the healthcare industry, and even for photo tagging.
It is used to extract data from visual inputs and use them to take action or provide recommendations.




















